LLMs 101: A Comprehensive Introduction to Large Language Models
LLMs are the most talked-about technology in software right now. Most people interact with them only through chat interfaces (e.g., ChatGPT). But understanding the mechanics underneath changes how you use them and how to set realistic expectations for what they can and can’t do.
Earlier this month, I gave a talk at the New York City AI Users Group going over all of that. This article is the written companion.
The Evolution of Natural Language Processing
Before LLMs, computers trying to understand language went through several distinct eras, each solving problems the previous one couldn’t.
-
Rule-Based
1950s-1980s
Handwritten Rules
-
Statistical
1990s-2012
n-grams, SVMs
-
Deep Learning
2013-2018
Embeddings, RNNs, Attention
-
LLMs
2019-Present
BERT, GPT, LLaMA
Rule-based (1950s-1980s). Linguists handwrote if-this-then-that rules to parse sentences. A rule for pluralization, another for verb tense, another for every grammatical edge case. Natural language has more edge cases than anyone can enumerate, so these systems were brittle by design and exhausting to maintain.
Statistical (1990s-early 2010s). Machine learning replaced explicit rules with probabilistic models trained on data. Hidden Markov Models scored likely word sequences for speech recognition, n-grams predicted words from how often they appeared near each other, and support vector machines classified text based on statistical features. This scaled better than rules, but it learned surface co-occurrence rather than meaning.
Deep learning (2013-2018). Word embeddings represented every word as a vector of numbers in a high-dimensional space, where words with related meanings landed close to each other. “King” sat near “Queen”, “Cat” near “Dog”, “Walking” near “Running”, etc.. This gave models access to semantic relationships that rules and statistics couldn’t reach. RNNs and LSTMs neural networks then layered sequential understanding on top, processing text word-by-word with a hidden state that carried context forward. This unlocked real language understanding for the first time. But RNNs read one token at a time, which meant they were slow since they couldn’t be properly parallelized, and their fixed-size hidden state lost track of information across long sequences.
Transformers
The attention mechanism was introduced to language models for machine translation in 2014 by Bahdanau et al., improving alignment between source and translated text. Instead of compressing an entire source sentence into a single fixed vector, attention let the decoder look back at every source token and decide which ones mattered for each output word.
Three years later, Google’s Attention Is All You Need paper pushed the idea to its extreme, throwing out RNNs entirely and building the Transformer architecture around self-attention, which let every token attend to every other token in a sequence in parallel. Combined with positional encoding, Transformers scaled in ways RNNs never could. Every modern LLM, from GPT to Claude to LLaMA, is built on this foundation.
If you want to go deeper on how self-attention actually works inside a Transformer, I highly recommend Jay Alammar’s The Illustrated Transformer.
How LLMs actually work
Training an LLM happens in three main stages, and each one costs a fraction of the step before it.
Alignment
Pre-Training
Learn language patterns from massive text data
SFT
Fine-tune on tasks with labeled data
RLHF
Refine with human feedback as reward
ICL or Fine-Tuning
Adapt via prompts/RAG or further training
Most expensive step (by far)
* Pre-Training: Most expensive step (by far)
Pre-training. At this stage, the model learns by playing fill-in-the-blank on massive amounts of raw text (books, websites, code, scientific papers). Words are hidden from sentences and the model has to predict them, over and over, trillions of times. For a sense of scale, Common Crawl, the open web archive that GPT-3 and most modern LLMs pull from, holds petabytes of raw web text. This is self-supervised learning at scale, where the labels come from the data itself. By the end, the model has a statistical representation of how language works, but it can only autocomplete. It doesn’t know how to follow instructions yet. Pre-training a frontier model costs tens of millions of dollars in GPU time, which is why this is by far the most expensive step in the pipeline.
Supervised Fine-Tuning (SFT). The pre-trained model is further trained on a curated dataset of prompt-response pairs. For LLMs, this is usually instruction tuning: teaching the model to answer questions, write code, summarize documents, and behave like an assistant rather than an autocomplete engine. Far cheaper than pre-training, but still non-trivial to do well.
Reinforcement Learning from Human Feedback (RLHF). The alignment step. Human raters compare pairs of model outputs and pick the better one, and those preferences train a separate reward model. The reward model then steers the LLM via reinforcement learning toward responses people prefer. RLHF is what gets a model closer to what Anthropic calls “helpful, harmless, and honest.” Without SFT and RLHF, base models will happily reproduce toxic or misleading patterns from their training data, because nothing has explicitly penalized those outputs.
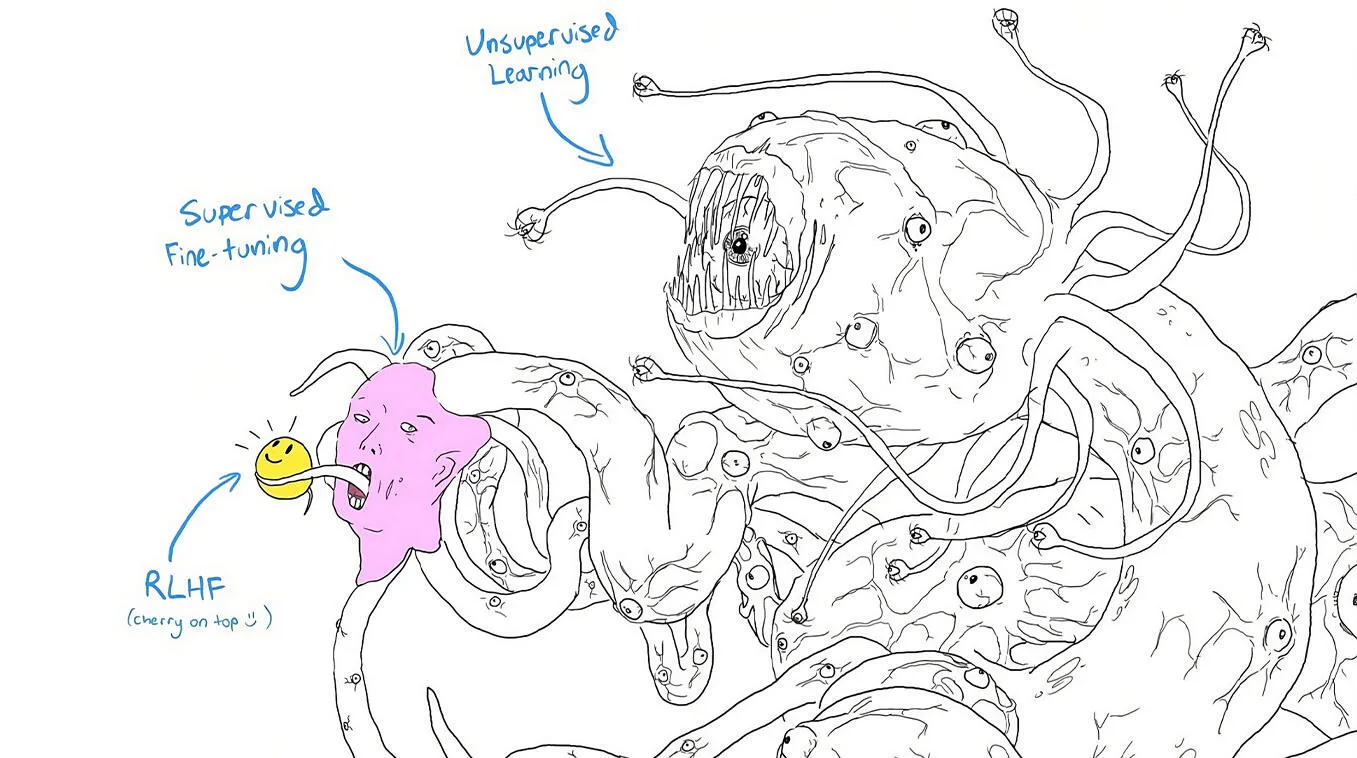
The ML community uses “Shoggoth with a smiley mask” as a meme to describe LLMs’ training process. The pre-trained model is drawn as a sprawling Lovecraftian monster, with SFT as a small pink face grafted onto one of its tentacles and RLHF as the smiley mask held up in front. The joke lands because the pipeline really does stack like that. The polished assistant you get to interact with is a thin layer of refinement sitting on top of a much larger and weirder pre-trained model.
Next-word prediction
Under the hood, text generation is simpler than it sounds. Given a sequence of tokens, the model calculates a probability distribution over its entire vocabulary for what comes next, driven by what the model learned from its training data, the preferences installed during SFT and RLHF, and the tokens currently in its context window.
The sky is ▊
For the prompt “The sky is”, the model might assign 47% probability to “blue”, 24% to “clear”, and smaller weights to options like “usually”, “the”, and “falling”. The model picks a token, appends it to the sequence, and repeats. That’s it. Every response you’ve ever gotten from an LLM was generated one token at a time, each one conditioned on everything before it, including the tokens the model itself just generated. The sophistication comes from the model’s ability to maintain coherent context over thousands of tokens while doing this, which is what the transformer architecture unlocked.
Tokens vs Words
LLMs don’t operate on words directly. They use tokens, which are sub-word units typically created through a process called Byte-Pair Encoding (BPE) or a similar algorithms. Common words like “the” are single tokens, but uncommon words get split into pieces. “Tokenization” might become “Token” + “ization”. This is why LLMs struggle with tasks like counting letters in a word or working with unusual character patterns. They literally don’t see individual characters the way we do.
You can see this in action using the Tiktokenizer playground, which visualizes how GPT’s tokenizer breaks text apart.
Limitations
Each of the three forces driving next-token prediction has hard edges. The training data has gaps and a cutoff date. Post-training can’t catch every bad output. The context window is finite, and the model can’t reach beyond it. The practical limitations below all trace back to one of those.
Hallucinations. LLMs generate plausible-sounding text, but they’re not designed to prioritize factual accuracy. They produce what statistically follows from the prompt, not what’s true. Ask an LLM how many ‘m’s are in the word “Weather” and it might confidently tell you there’s one, then apologize and correct itself when challenged. The model isn’t lying. It’s doing math on token probabilities, not reasoning about spelling.
Limited context windows. Every LLM has a maximum amount of text it can process at once. In early 2024, GPT-4 Turbo’s window is 128K tokens, Claude 2.1 offers 200K. That may sound like a lot until you’re building an application that needs to process long documents or maintain extended conversations.
Outdated knowledge. LLMs know what was in their training data, and nothing else. A model trained on data up to April 2023 has no idea about events after that date.
Limited to generating text. An LLM can write a perfect email, but it can’t send it. It can describe a database query, but it can’t execute one. On its own, an LLM is confined to generating text, and turning that text into action requires additional engineering.
Working around the limitations
Each limitation has a practical workaround. Training data and post-training preferences are locked in once the model ships, so every technique below comes down to shaping the one force you still control, the context the model is generating into.
Prompt engineering
The most direct way to shape the context. A vague prompt gets a vague response. A specific prompt with clear constraints, role-setting, and format requirements gets dramatically better output.
Bad prompt: “Suggest some books.” gets you a generic list of classics.
Good prompt: “Recommend contemporary novels that weave themes of AI ethics and human dilemmas, preferably from authors recognized for their deep exploration of technology’s impact on society.” gets you targeted, useful recommendations.
Few-shot prompting
Instead of explaining what you want in the abstract, show the model examples. One-shot prompting gives a single example. Few-shot prompting provides two to five examples of input-output pairs. The model picks up on the pattern and generalizes, since the examples are right there in the context it’s conditioning on. This is particularly effective for formatting, classification, and translation tasks where showing is faster than telling.
Chain of thought
Complex tasks can overwhelm an LLM when presented all at once. Chain of thought prompting breaks the problem into explicit steps, asking the model to show its reasoning. Because each reasoning step becomes part of the context the next tokens condition on, the final answer is built on top of the scaffolding the model just wrote for itself. This significantly improves accuracy on math, logic, and multi-step reasoning tasks. A model that gets the wrong answer when asked directly often gets the right answer when asked to work through the problem step by step.
Prompt chaining
This is where things get interesting for application builders. Instead of cramming everything into a single prompt, you break the workflow into a sequence of LLM calls. Each call handles one well-defined step, and the output of one becomes the input to the next. Humans can review intermediate outputs before the next step fires. This pattern is the backbone of most production LLM applications, and it’s exactly how the talk’s demo was built.
Retrieval Augmented Generation (RAG)
RAG addresses the outdated knowledge and hallucination problems by injecting fresh information into the context. Before sending a prompt to the LLM, you search a knowledge base (using vector embeddings and a vector database like Chroma or Pinecone) to find relevant documents. Those documents get injected into the prompt as context, grounding the model’s response in actual, up-to-date information.
Without RAG
Question
For which club does Lionel Messi play?
Prompt
Answer the following question to the best of your abilities: For which club does Lionel Messi play?
LLM Response
As of my latest update in 2021, Messi plays for Paris Saint-Germain FC.
With RAG
Question
For which club does Lionel Messi play?
Retrieved Context
Messi has signed with Inter Miami CF, joining David Beckham's club until 2025.
source: news article
Prompt
Based on the following context: Messi has signed with Inter Miami CF, joining David Beckham's club until 2025.
Answer the following question: For which club does Lionel Messi play?
LLM Response
Lionel Messi plays for Inter Miami CF.
For example, asking “For which club does Lionel Messi play?” on a model with a 2021 training cutoff gets you the confidently wrong answer “Paris Saint-Germain.” Feed it a retrieved news snippet about Messi’s 2023 Inter Miami signing in the prompt, and the same model answers correctly.
The difference is stark. Without RAG, the model relies on whatever it learned during training. With RAG, it gets current, source-backed context and produces accurate answers. This is how most enterprise LLM deployments work in practice.
Function calling
Function calling lets the LLM trigger real actions. Instead of just describing what should happen, the model’s output becomes structured data that your application code can act on, with the tool’s response flowing back into the context for the next generation step. Summarize data and then generate a chart from it. Answer a question and then log the interaction. This bridges the gap between “language, not action” and actual utility.
The LLM Landscape
Choosing an LLM in 2024 means navigating two distinct paths:
- Open source models (LLaMA, Mistral) give you full control. You can inspect the weights, fine-tune for your domain, run locally, and avoid per-token API costs. The tradeoffs are real though: you need significant compute to run them, they currently lag behind proprietary models on most benchmarks, and community support, while active, is no substitute for enterprise SLAs.
- Proprietary models (GPT-4, Gemini, Claude) are easier to get started with, offer better raw performance, and come with commercial support. The downsides are cost (API calls add up fast, and fine-tuning is expensive), vendor lock-in, and opacity. You can’t see how the model works or why it made a particular decision.
For evaluating models, a handful of benchmarks do most of the work. MMLU (Massive Multitask Language Understanding) covers 57 subjects from STEM to humanities and is the go-to measure of general knowledge. HumanEval measures functional correctness on 164 programming problems generated from docstrings. The model’s output has to actually run and pass the tests. HellaSwag probes commonsense reasoning with questions humans solve more than 95% of the time but that still trip up state-of-the-art models. And Chatbot Arena sidesteps static benchmarks entirely, using head-to-head ELO ratings from crowd-sourced blind comparisons. As of February 2024, GPT-4 variants hold the top spots in the Arena, with Gemini Pro, Mistral Medium, and Claude competing in the top 10.
The tooling ecosystem has matured rapidly. LangChain and LlamaIndex provide frameworks for building LLM-powered applications. Chroma and Pinecone handle vector storage for RAG. Ollama makes running open source models locally trivial. Axolotl simplifies fine-tuning. Replicate offers LLMs as a service. The ecosystem is moving fast, but these are the stable anchors.
Putting it all together: Super Bowl Ad Brief Generator
To make all of this concrete, I built a demo for the talk. The Super Bowl Ad Brief Generator takes a one-sentence product description (“dog food that makes dogs able to talk”) and uses prompt chaining to turn it into a full creative advertising package.
The pipeline is five GPT-4 Turbo calls wired together via LangChain, running idea description → creative brief → creative concepts → script → storyboard, with DALL-E 3 generating the final visual panels. Every stage parses the model’s output into a typed Pydantic schema, so a bad response fails loudly at the boundary instead of corrupting the next prompt.
The repo has the slides, notebook, and source: github.com/SabriDW/LLM-101-Talk-NYCAIU. You can run the full pipeline end-to-end in Google Colab with just an OpenAI API key.
Use responsibly
LLMs are powerful, but they carry real risks that scale with deployment.
Bias is inherited from training data. If the data contains stereotypes, the model reproduces them. Hallucinations mean you need verification layers for anything factual. Privacy is a concern when user data flows through third-party APIs. And the computational cost of training and running these models has a real environmental footprint.
One distinction matters above the rest. LLMs can sound equally confident when they’re right and when they’re wrong, and they rarely signal the difference. Treat output you care about as a draft that needs human review before you rely on it.
The field is moving fast. New models, techniques, and tools emerge weekly. But the fundamentals covered here (how transformers work, how LLMs generate text, the failure modes, and how to build around them) are the stable foundation everything else is built on.
Tags: #ai #llm